Sinds de vaststelling van het SARS-CoV-2-virus in december 2019 is het aantal wiskundige modellen over dit virus sterk toegenomen. Vele wiskundigen pogen de verspreiding van het virus en het effect van maatregelen om verspreiding te beperken, te voorspellen. Sommige van deze modellen worden gebruikt om politici advies te geven over strategieën om het land door de epidemie heen te leiden. Een duidelijk voorbeeld hiervan is de start van de zogeheten ‘intelligente lockdown’ halverwege maart, gebaseerd op adviezen van het Outbreak Management Team.
Belangrijke resultaten van wiskundige modellen zijn het aantal besmettingen en het aantal met COVID-19 besmette individuen die zorg op een intensive care (IC)-afdeling nodig hebben. Om te bepalen hoeveel IC-bedden er nodig zijn voor met COVID-19-besmette patiënten, moeten we niet alleen weten hoeveel besmettingen er zijn, maar ook wie van de besmette patiënten opgenomen dienen te worden op de IC en wat de duur van een IC-opname is. Beide variabelen beïnvloeden de hoeveelheid IC-bedden die er landelijk bezet zijn en daarmee de druk op de zorg.
Maatregelen om transmissie te voorkomen, hebben echter een vertraagd effect op het aantal IC-opnames, vanwege de tijd tussen besmetting en opname. Voor goede schattingen van het aantal opnames van patiënten met COVID-19 zijn er dan ook gedetailleerde modellen nodig die rekening houden met de vertragingen in besmetting en opname. Daarnaast is het van belang dat een model representatief is voor de populatie waarover vragen gesteld worden. De grootte van een populatie, maar ook de leeftijdsstructuur van een populatie, zijn van belang. Niet alleen omdat de kans op een ernstige variant van de infectie leeftijdsafhankelijk is, maar ook omdat contacten tussen individuen, en daarmee transmissie, leeftijdsafhankelijk zijn. Wanneer naast grootte en leeftijdsstructuur van een populatie, ook nog mate van transport en gezondheidszorg worden meegenomen als parameters van het model, worden de uitkomsten steeds gedetailleerder. Des te meer de virtuele kopie van een stad of land, dat wil zeggen het wiskundige model, lijkt op de realiteit, des te gedetailleerder de uitkomsten kunnen worden. Met dien verstande, dat een gedetailleerd model noodzakelijkerwijs ook veel parameters bevat en dat de betrouwbaarheid van een gedetailleerd model alleen hoger is als er goede schattingen zijn van de parameters. Als dat niet zo is, zoals bij een uitbraak van een nieuwe infectieziekte, zijn simpele modellen vaak beter, omdat die beter te begrijpen en te valideren zijn.
Het SEIR-model
Veel van de ontwikkelde modellen zijn varianten van het zogeheten SEIR-model. Het SEIR-model is een karikaturaal model voor de verspreiding van een besmettelijke ziekte in een populatie. De basisvariant van het SEIR-model houdt geen rekening met demografie, ruimtelijke of andere details van een populatie, maar het neemt wel mee dat iemand die besmet is, niet direct zelf besmettelijk of ziek is. Het model beschrijft een populatie van N individuen, waarbij individuen onderscheiden worden op basis van vier mogelijke ziektetoestanden. Dit zijn de vatbaren (Susceptible) die de ziekte nog niet hebben doorgemaakt, latent geïnfecteerden (Exposed), oftewel individuen die nog geen symptomen hebben en nog niet besmettelijk zijn, besmettelijke individuen (Infectious) die vatbaren kunnen besmetten, en individuen die genezen zijn en immuun (Recovered).
Voor het gemak nemen we aan dat iedereen die de ziekte heeft doorgemaakt levenslang immuun is en niet zal terugkeren als vatbaar. Besmettelijke individuen die overlijden aan COVID-19 kunnen niemand meer besmetten en die scharen we dus onder de immune individuen in het R-compartiment. Hoewel dit er vreemd uitziet - genezing en overlijden zijn immers totaal verschillende gebeurtenissen - kunnen we het aantal mensen dat op een bepaald tijdstip is overleden aan de ziekte altijd bepalen als we de grootte van het R-compartiment kennen en weten welk deel van de mensen die de ziekte doormaakt, immuun wordt en welk deel overlijdt. Het SEIR-model veronderstelt verder dat contacten willekeurig zijn, met andere woorden als 10 procent van de populatie besmettelijk is, is gemiddeld ook 10 procent van de contacten een contact tussen een vatbaar en een besmettelijk individu.
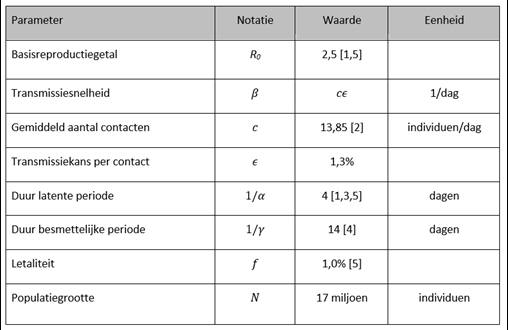
Het model zoals hierboven beschreven en weergegeven in figuur 1 bevat drie parameters, 1) de gemiddelde duur dat iemand in de latente periode zit, 2) de gemiddelde duur dat iemand besmettelijk is en 3) het basisreproductiegetal, R0, het gemiddeld aantal mensen dat door één besmet individu besmet wordt aan het begin van de epidemie wanneer (vrijwel) alle contacten van een besmettelijk individu met vatbare individuen zijn. Een R0 groter dan 1 betekent dat het aantal besmettingen kort na de introductie van de ziekte stijgt en dat er een epidemie kan optreden, doordat een besmet individu meer dan één ander individu besmet. Als we starten met één besmettelijk individu (generatie 0), zijn er in generatie één, gemiddeld R0 besmettelijke individuen, in generatie twee R02, in generatie drie R03 enzovoort. Het aantal besmettelijke individuen per generatie groeit exponentieel aan het begin van de epidemie en binnen een paar generaties is het aantal besmettingen groot. Voor SARS-CoV-2 is het basisreproductiegetal in de orde van 2,5.[1,5]
Een R0 wordt daarnaast ook gebruikt om te berekenen hoeveel procent van de populatie immuun moet raken voor groepsimmuniteit voor het SARS-CoV-2-virus. Als een percentage 100 (1-1/R0) van de populatie immuun is - voor R0 = 2,5 is dit 60% - is er groepsimmuniteit en zal geen grote epidemie meer optreden als het virus opnieuw wordt geïntroduceerd. Wanneer een besmettelijk individu in afwezigheid van immuniteit R0 mensen besmet en een fractie 1/R0 van de populatie vatbaar is, zal dit individu gemiddeld precies één nieuw individu besmetten.
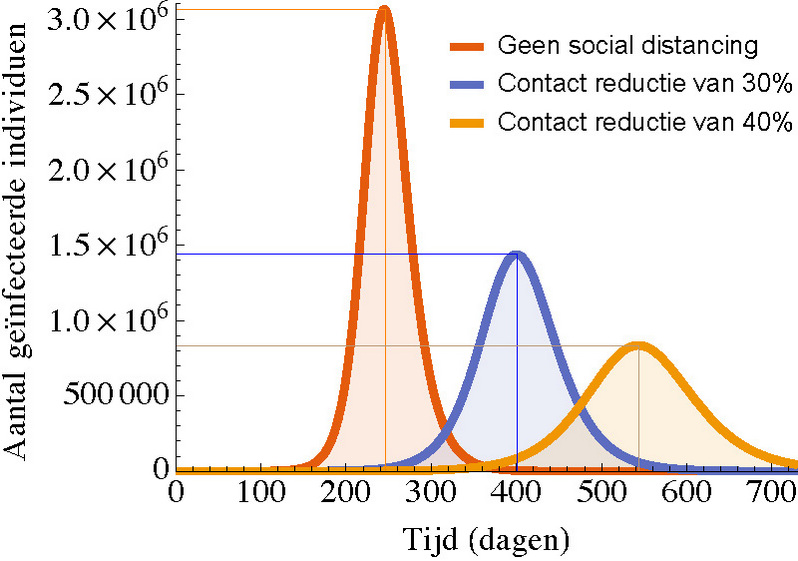
Zonder maatregelen en/of gedragsverandering, en uitgaande van het simpele SEIR-model, raakt bij een basisreproductiegetal van 2,5 uiteindelijk 89 procent van de populatie besmet; voor een gemiddelde duur van de latente periode van vier dagen en een gemiddelde duur van de infectieuze periode van 14 dagen is op de piek van de epidemie 18 procent van de populatie ziek (zie figuur 2). Ondanks de sterke simplificaties van het model en ondanks de opgebouwde groepsimmuniteit, laat dit zien dat een ongecontroleerde epidemie niet wenselijk is, aangezien tijdens de piek van de epidemie dan ruim 3 miljoen inwoners geïnfecteerd zijn. De reden dat er meer mensen besmet raken dan nodig om groepsimmuniteit te krijgen is dat op het moment dat er groepsimmuniteit is in de populatie, er nog heel veel besmettelijke individuen zijn. Deze mensen besmetten dan gemiddeld weliswaar per persoon minder dan één individu, maar ze besmetten nog een substantieel deel van de populatie.
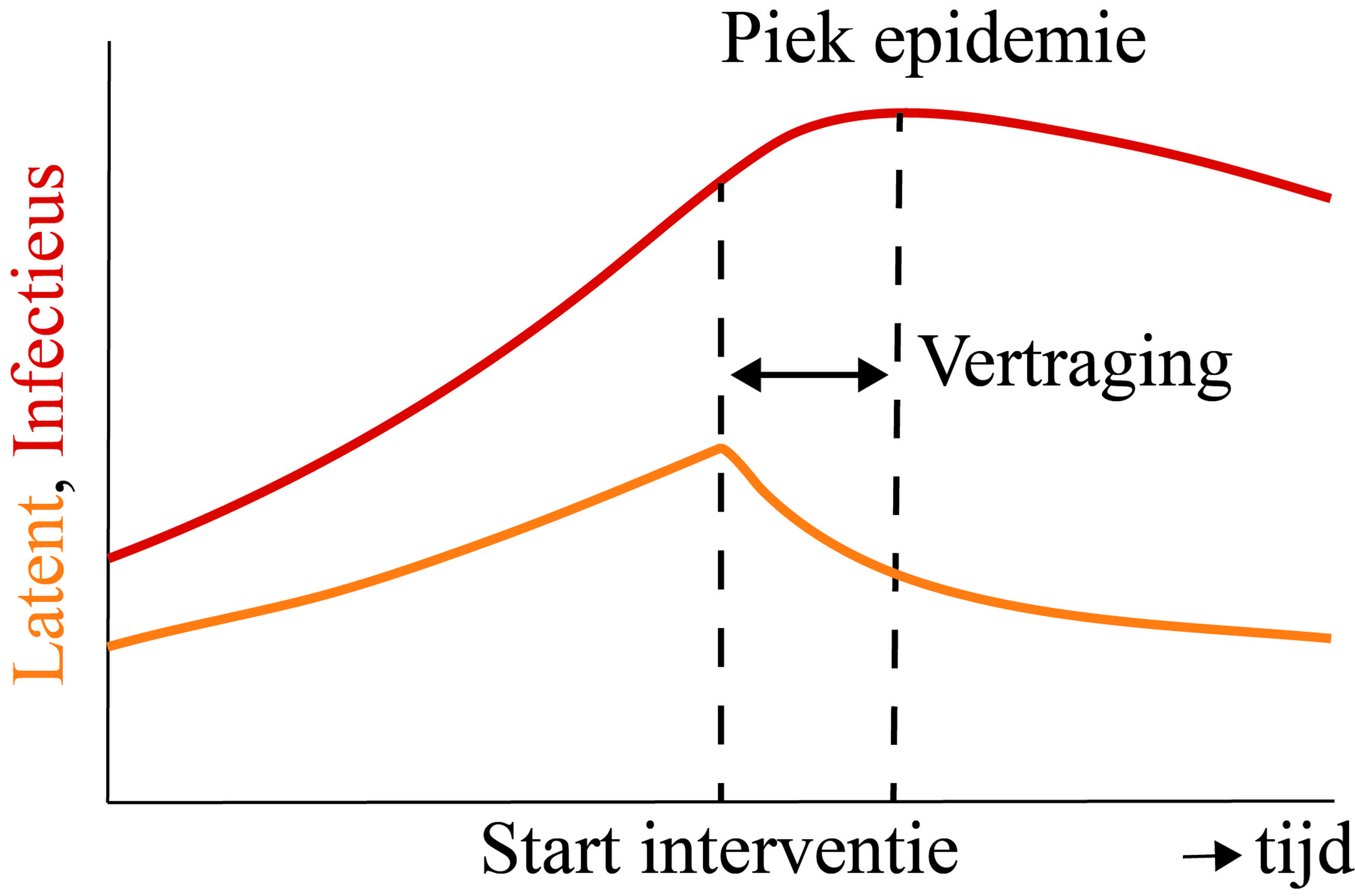
Stel nu, zoals in werkelijkheid ook gebeurd is, dat er gedurende de fase waarin het aantal besmettingen nog exponentieel groeit, maatregelen worden genomen die de transmissie beperken. Dan heeft dit direct effect op het aantal nieuwe besmettingen, maar het aantal mensen dat infectieus is, blijft nog even stijgen en daalt pas na verloop van tijd (zie figuur 3). Dit effect treedt in versterkte mate op bij het aantal IC-opnames, omdat de tijd tussen besmetting en IC-opname groter is dan de tijd tussen besmetting en besmettelijk worden. Alleen uitgaande van R0 is het dus niet mogelijk om te bepalen hoe snel het aantal IC-opnames daalt vanaf de introductie van maatregelen. Om het aantal IC-opnames te voorspellen is het noodzakelijk om voor de afgelopen weken per dag te weten hoeveel nieuwe besmettingen er die dag hebben plaatsgevonden in combinatie met een goed model dat beschrijft hoe lang het duurt voordat een besmet individu op de IC belandt en hoe lang een IC-patiënt daar verblijft. Zeker in het begin van de epidemie is er in al deze factoren een behoorlijke mate van onzekerheid en bevat de voorspelling van het aantal bezette IC-bedden ook een behoorlijke mate van onzekerheid.
In figuur 2 zien we dat een contactreductie van 30 en 40 procent leidt tot een lagere piek van het aantal geïnfecteerden en dat het langer duurt voordat de piek optreedt. Veel stringentere maatregelen, bijvoorbeeld een contactreductie van minstens 60 procent, zullen ervoor zorgen dat de epidemie de kop in wordt gedrukt.[6] Het nadeel is dat ook vrijwel niemand in de populatie immuniteit heeft opgebouwd en je deze contactreductie zult moeten handhaven totdat er een vaccin beschikbaar komt. Een alternatief is de epidemie gecontroleerd door de populatie te laten gaan. Aan de hand van een rekenvoorbeeld laten we zien dat dit enige jaren zal duren. Stel dat we in Nederland langdurig 600 IC-bedden reserveren voor COVID-19-patiënten en dat de gemiddelde IC-duur voor COVID-19-patiënten 30 dagen is. Van de 600 COVID-19-patiënten verlaten er dan gemiddeld (600/30=) 20 per dag de IC. Dat betekent dat er ook maximaal 20 nieuwe patiënten op de IC opgenomen mogen worden zonder dat het aantal vereiste IC-bedden stijgt. Als gemiddeld 1 procent van de met SARS-CoV-2 besmette individuen op de IC belandt, dan mogen er per dag maximaal 2000 mensen besmet worden. Voor groepsimmuniteit moet 60 procent van de populatie de besmetting hebben gehad, dat correspondeert met 10 miljoen mensen. Het kost dus 5000 dagen van 2000 besmettingen per dag, om groepsimmuniteit te krijgen. Deze simplistische berekening laat zien dat het vele jaren duurt voordat er groepsimmuniteit zal zijn.
Met dit simpele SEIR-model is het al mogelijk om het aantal geïnfecteerde individuen te voorspellen. Daarnaast is het ook mogelijk om effecten van maatregelen, in dit geval social distancing, in te bouwen in het model en het effect op het aantal geïnfecteerden te onderzoeken. Complexere modellen zijn nodig om de effecten van exitstrategieën te voorspellen als de maatregelen leeftijds- of tijdsafhankelijk zijn. Deze modellen zullen ook laten zien dat er langdurig maatregelen nodig zijn, maar gedifferentieerde interventies kunnen de impact van de maatregelen mogelijk wel verminderen.
Ander soort modellen
Het doorrekenen van een model zoals bovenstaande zal te allen tijde eenzelfde voorspelling geven. Om meer willekeurigheid toe te voegen, kunnen zogenoemde stochastische modellen gebruikt worden. Deze modellen werken op basis van het gooien van een virtuele munt of bijvoorbeeld een vatbaar individu besmet raakt wanneer deze in contact komt met een besmettelijk individu. Meer willekeur maakt het model realistischer, en vergroot de onzekerheid over de hoeveelheid IC-opnames.
Realistische modellen die de IC-capaciteit willen voorspellen, zullen meer detail moeten bevatten dan het basis-SEIR-model: Individuen worden vaak onderverdeeld in populatiegroepen gebaseerd op onderlinge overeenkomsten als geslacht, leeftijd, en risicofactoren. Opsplitsen is zinvol als uit goede data is gebleken dat er associaties bestaan tussen populatiefactoren en IC-opname, zoals bij leeftijd het geval is gebleken. Het blijven opsplitsen van populatiegroepen in meer representatieve subpopulaties zal de realiteit beter weergeven, maar maakt een model toenemend gecompliceerder. Een andere manier om naar de populatie te kijken is het gebruik van Individual Based Models (IBM’s). Hier wordt aan elk individu een bepaald aantal regels toegeschreven over hoeveel contacten ze hebben, wat voor transport ze gebruiken en wat ze in een dag kunnen doen. Elk individu heeft dan de vrijheid om zich uniek te gedragen, wat het model dichter bij de realiteit brengt. Een groot nadeel van deze modellen is dat er veel data nodig is over individuen en een model met een grote populatie al snel erg gecompliceerd wordt.
Welk model te kiezen?
De keuze voor een wiskundig model om de uitbraak van SARS-CoV-2-virus te voorspellen en om te berekenen hoeveel IC-opnames verwacht kunnen worden is afhankelijk van de probleemstelling, en de hoeveelheid en betrouwbaarheid van beschikbare data. In het begin van een epidemie, wanneer nog veel onzeker is, zal sneller gekozen worden voor een simpeler, maar minder realistisch model, terwijl de mate van realiteit van het model kan stijgen wanneer er meer epidemiologische data bekend worden; die stijging kan doorgaan zolang het model binnen afzienbare tijd tot resultaten leidt. De prestatie van een model zal echter altijd pas achteraf getoetst kunnen worden, wanneer de tijd een voorspelling heeft ingehaald. Voor de toekomst zal blijven gelden dat hoe verder weg in de toekomst een voorspelling ligt, hoe minder zeker deze zal zijn. Het is dus van belang de resultaten van een model goed te interpreteren op basis van de aannamen waarop het gebouwd is. Daarmee valt te zien welke uitspraken robuust zijn en waar de grenzen van de modelmatige analyse liggen. Daarnaast kan de prestatie van een model worden beïnvloed door de correctheid van de data. Het model zelf kan correct opgesteld zijn maar toch sterk afwijkende resultaten leveren wanneer een of meerdere parameters afwijken van de realiteit. Een belangrijke taak van de makers van deze modellen is dan ook om de achterliggende modelaannamen en de gekozen parameterwaarden duidelijk te beschijven.
Kortom, wiskundige modellen zijn in staat een beeld te geven van het ziekteverloop bij de SARS-CoV-2-uitbraak in maart 2020. Deze modellen kunnen dan ook gebruikt worden om effecten van maatregelen voor bijvoorbeeld transmissiepreventie zichtbaar te maken. Op basis hiervan kan men politici adviseren welke strategieën passend zijn voor de bestrijding van het virus.

 \
\